Topic 10
Further Sorting Algorithms
Warning!
This is a more advanced topic which is not compulsory for passing the assignment, but will be useful for higher marks. It's included here to give those of you who are coping reasonably well with the module an idea on how more advanced and efficient sorting algorithms work.
If you need to catch up with previous weeks, please do this first!
Introduction
Two weeks ago we covered some basic sorting algorithms, such as bubble sort, selection sort and insertion sort. However, we saw that their efficiency could be better, being O(n^2) in the worst case. This week we will look at two improved sorting algorithms, quicksort and merge sort.
These algorithms use recursion. Please see the trees topic for a reminder on recursion.
Quicksort
Quicksort is the first of the two algorithms. It works by recursively partitioning the list into two sections, or partitions, either side of an element we call the pivot.
An arbitrary element (e.g. the last, the middle, or the first) is picked as the pivot, and then the partitioning phase begins. The aim of the partitioning phase is to rearrange the list so that it all the elements less than the pivot element are to its left, and all elements greater than the pivot element are to its right. To do this, the partitioning phase re-arranges the list, performing a series of swaps so it is ordered correctly.
The general procedure is shown below.
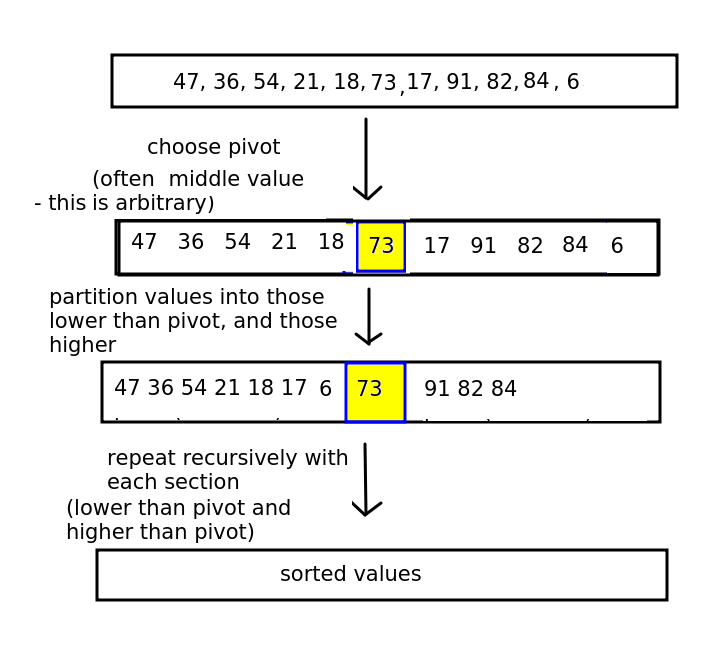
Next stage is to recursively perform the quicksort again on the partition before the pivot, and the partition after the pivot - as the elements in each partition will not be sorted yet, all we know is that the pivot is in the correct place. Each partition will have the algorithm applied to it (so that each parititon will have its own pivot, and the partition will be sorted into the sub-partition less than the partition's pivot, the partition's pivot, and the sub-partition greater than the pivot).
The procedure continues until the entire list is sorted.
This is a very high level overview and the implementation details are not obvious at this stage. We have to consider the partitioning stage (working out which elements are less than, and which greater than, the pivot) in more detail. There are various approaches to this; we will use the Hoare partitioning algorithm.
Quicksort, like the other sorting algorithms we have looked at so far, is an in-place sorting algorithm. This means that we perform the complete algorithm within the original list and sort the original list: we do not need to create any new lists to perform quicksort. Each recursive step takes in as parameters the list, and the start and end index of the current partition.
The Hoare partitioning algorithm
Described on Wikipedia and cross-checked against various academic sources including this one from Stanford University.
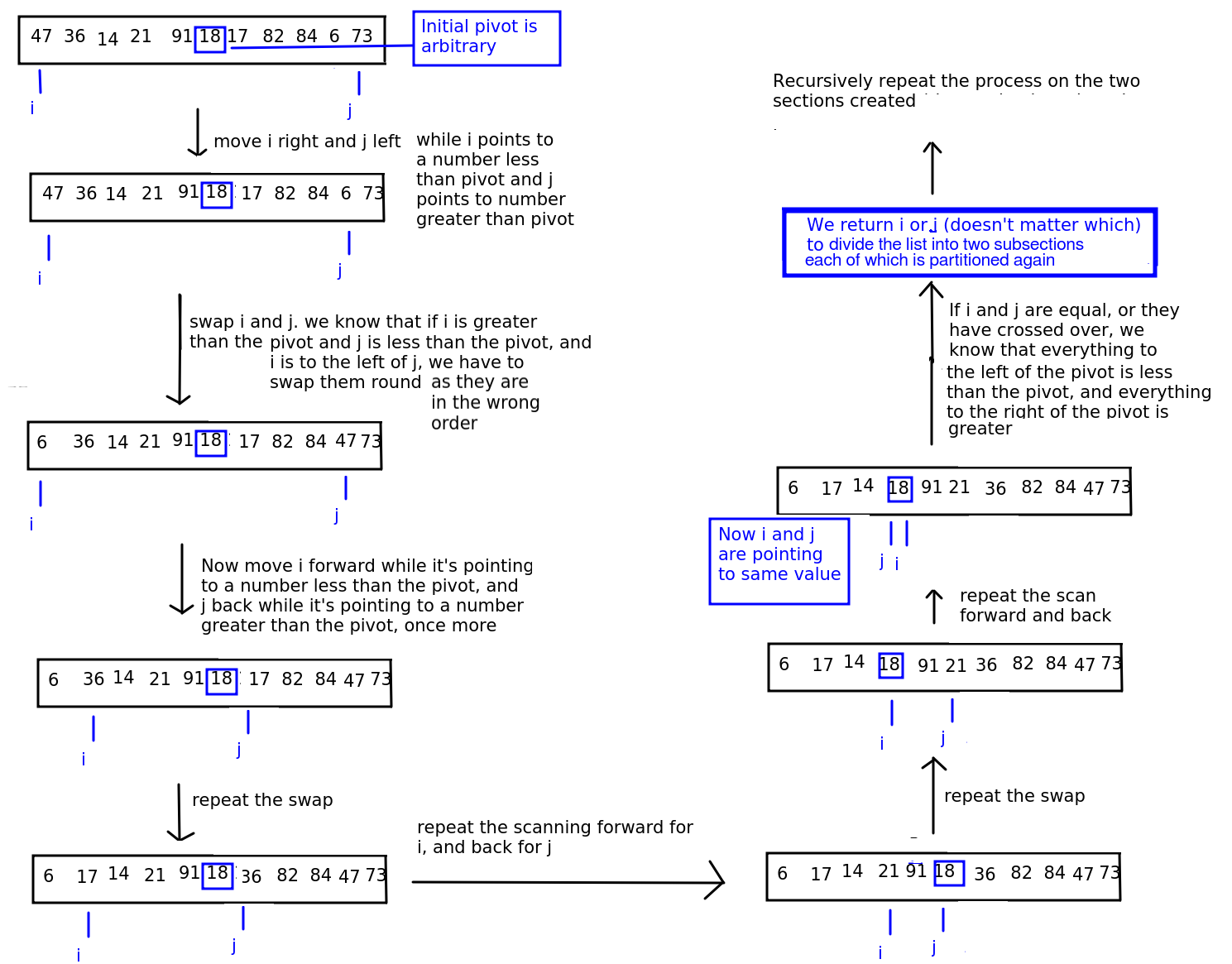
The Hoare algorithm (developed by the well-known mathematician and computer scientist Tony Hoare, as was quicksort itself) works by having two "fingers" (term "finger" from notes by Brian Dupée, which were in turn sourced from the site sorting-algorithms.com) pointing to the start of the list and end of the list. We move the first "finger", referenced by the variable i forwards and the second "finger", referenced by the variable j, backwards, until i points to something GREATER THAN OR EQUAL TO the pivot and j points to something LESS THAN OR EQUAL TO the pivot.
As we move each "finger" forward and back, we test whether any valuse need to be swapped. If the value at i is greater than the value at j, and i is still to the left of j, then we know that the values are in the wrong order and we swap them.
When i and j point to the same element (the pivot) or cross over (j is to the left of i), then we know that we have done all the swaps we can, because i will have scanned all values greater than the pivot which were to the left of the pivot (and have now been swapped), and j will have scanned all values less than the pivot which were to the right of the pivot (and have now been swapped).
We return the new partition point (which will be either j or i - often they will point to the same value) so we can continue the operation recursively.
The algorithm is shown on the diagram below.
The quicksort function then:
- gets a new pivot by calling the Hoare partitioning algorithm;
- recursively calls quicksort on the section left of the pivot and section right of the pivot.
The recursion will stop when we have a list section of length 1 as it cannot be partitioned.
Progressive sorting of quicksort using recursion
We have covered the Hoare algorithm for sub-partitioning a partition, however it may not be clear how the quicksort algorithm progresses as a whole. In order to implement quicksort, we also need a "master" quicksort function which will recursively call itself in order to recursively sub-partition the list into smaller and smaller partitions. This will take, as parameters, our list, together with indices for the start and end of the current partition. Initially these indices should be set to the start and end of the list. The "master" function should then:
- If the partition has a length of at least 2 (and thus can be sub-partitioned):
- use Hoare partitioning (by calling our Hoare partitioning function) to partition the list and find a pivot;
- recursively call the "master" function passing in the partition before the pivot we found from Hoare, in order to sub-partition this section of the list;
- recursively call the "master" function passing in the partition after the pivot, in order to sub-partition this section.
- Or, return immediately if the partition has a length of 1. We cannot sub-partition any further and the process stops; we return from the function and descend the recursion stack to the previous call.
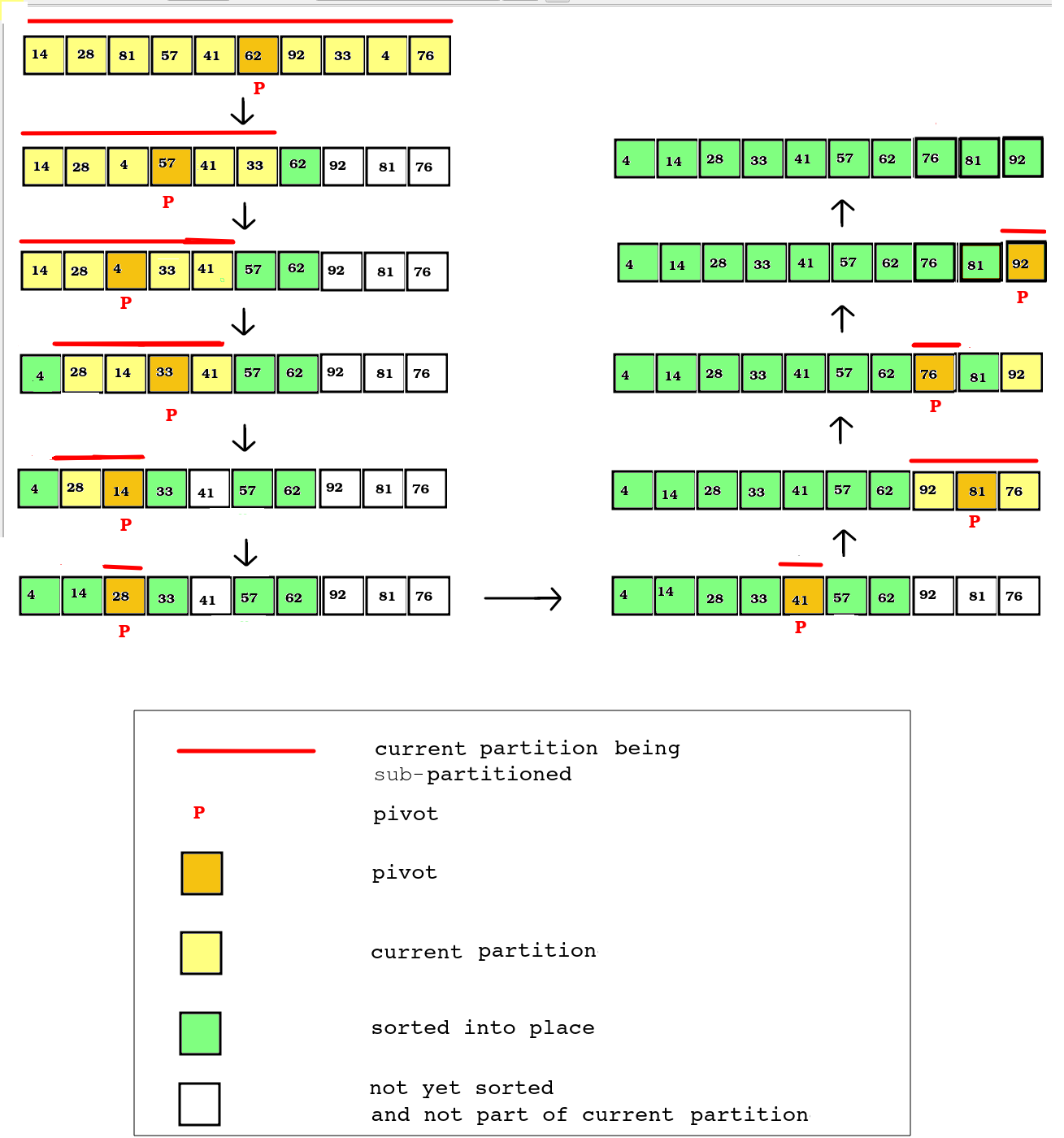
The diagram below shows how, with each run of the Hoare partitioning algorithm, the list is progressively sorted into place.
- Note how we progressively partition the list into smaller and smaller sub-partitions. We first partition the entire list, by selecting one of the centre two elements (62) as the pivot and partitioning the list into those values less than 62 and those greater than 62.
- We then end up with two sub-partitions, one consisting of the first 6 elements of the list (those values less than 62) and the second consisting of the final three elements (those values greater then 62). Furthermore, as a result of this partitioning, the value 62 has been sorted into place (in its correct place in the list)
- We repeat the process with the first of these two partitions (the first six elements) by selecting a new pivot (57) and sub-partitioning into those values less than 57 and those values greater than 57 (none). The value 57 has now been sorted into place.
- We then end up with just one sub-partition as all the other numbers in the previous step were less than the last pivot (57). The new pivot is 4 as it's the midpoint. Again this will only produce one sub-partition as all numbers are greater than 4. 4 is sorted into place.
- We then end up with the values 28, 14, 33 and 41 in the current subpartition. The new pivot is 33. This time we end up with two partitions: 28 and 14 (less than 33) and 41 (greater than 33). 33 is sorted into place.
The process repeats until all numbers are sorted.
Complexity of quicksort
The complexity of quicksort can be as low as O(n^2) in unusual cases but on average O(n log n). Why is this?
This is discussed in detail on Khan Academy but an overview is given below.
If the pivot is well-chosen and splits the list into two nearly-equal pieces on each run of the algorithm. So the maximum partition size halves each time we split ,and thus the number of splits required until we reach list sizes of 1 should be log n in the ideal case.
Then we need approximately n operations with the Hoare partitioning algorithm, for each level of recursion. With the initial (whole-list) partition we may need to do up to n swaps (slightly less due to the pivot) with the Hoare algorithm in the worst case. Then, when we split the list into two partitions, each partition only needs approximately 0.5n swaps, but add those together and you get approximately n. Similarly, when we further split the list into four partitions, each partition only needs approximately 0.25n swaps, but again, add those together and you get approximately n. So for each recursion level, approximately n (slightly less due to the pivots) operations are needed.
If we multiply the number of recursion levels with the number of operations per level, we thus get O(n log n).
However if we don't choose our pivot well, we could end up with one partition containing all members besides the pivot. The case below shows a worst-case each time, where just one partition is created, all members other than the pivot (note that * indicates members sorted into their correct place):
We can see here that n levels of recursion are required in a worst case. Thus we have n levels multiplied by approximately n operations per level which gives us O(n^2).
Merge sort
Reference: Khan Academy
Merge sort is another more advanced sort which continuously splits the list into equal parts until single elements are produced. For example, a list of length 8 would be split into two parts of length 4, then four parts of length 2, then eight single-item lists. Or, a list of length 10 would be split into two parts of length 5, then each part would be split into two parts of length 2 and 3, then each length 2 part would be split into two parts of length 1 while the length 3 part would be split into one part of length 1 and another of length 2, the latter of which would be split again. This is shown on the diagram below; the split phase is shown by the stages using red lines.
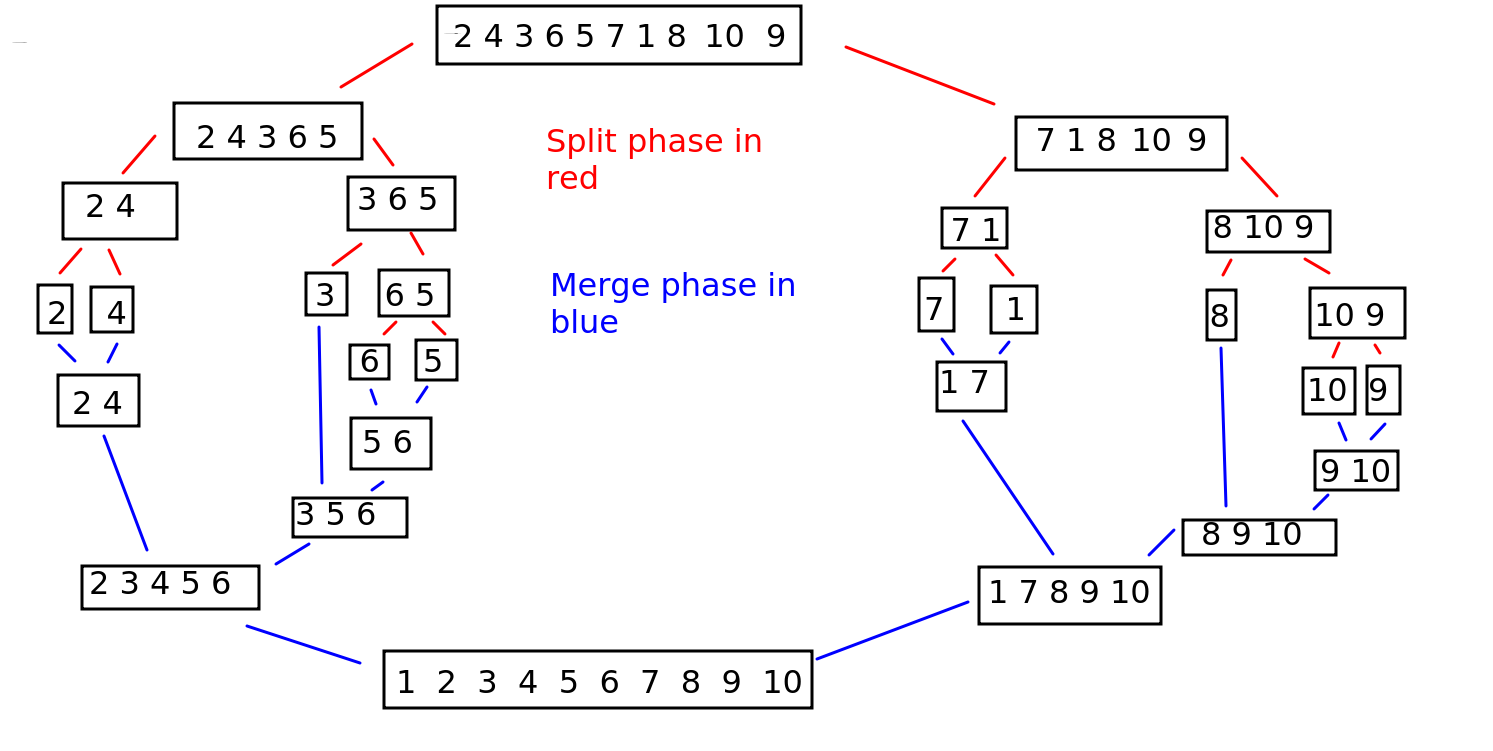
Once a split has happened, the components are recombined in sorted order. So a split of a 2-member part into two 1-member parts would be recombined into a 2-member part, but in sorted order. If a 3-member part was split into 1-member parts and 2-member parts, these would be recombined into a 3-member part, but again in sorted order. So the list gradually reassembles itself into its full length, but this time in sorted order. This is shown on the same diagram above; the merge phase is shown by the stages using blue lines.
How do we merge two parts so that they are in sorted order? The algorithm is as below. Also see Khan Academy for a detailed explanation.
Let's consider merging the two 2-member lists [2,4] and [3,5,6] as shown on the diagram below. A very important point is that when merging lists, we know that the previous lists will already be sorted from the previous run of the merge algorithm..

- We implement a
whileloop to continue running until we reach the end of the shorter list. - The first time the loop runs, we compare the first members of each list and add the lowest to the output list. Here, 2 is lower than 3, so we add 2.
- This will move the counter on one place for the first list, but keep it the same place for the second list. This is what we want, as we no longer need to consider the first member of the first list (as it's been placed in our output list), but we do need to consider the first member of the second list.
- So the second time the loop runs, we compare the second member of the first list (4) with the first member of the second (3). This time, it's the member in the second list which is lowest, so we add it to the output list:
and move the counter for the second list on one place.
- The third time the loop runs, we compare the second member of the first list (4) with the second member of the second list (5). Again, the member in the second list is lower, so we add it to the output list:
At this point, the counter for the first list will be beyond the end of the first list, so the loop exits. However, we still have two members (5 and 6) to be considered from the second list, so we add the remainder of the longer list elements (5 and 6) to the output list.
Implementing merge sort
You will need these functions:
- A function to split the list into two.
- A function to merge the sublists in sorted order, as described above.
- A recursive "manager" function, describe below.
Recursive approach to merge sort
The entire merge sort algorithm is handled with a recursive "manager" function. This recursive function takes a list to be split as a parameter, and:
- Splits the list into two by calling the split function.
- Recursively calls itself again on each half of the list, as long as the length of that half is greater than 1 (obviously a sublist of length 1 doesn't have to be split again!). Note that the "manager" function returns a sorted combined list.
- To understand what happens here, try thinking of it in reverse, by considering the topmost calls on the recursion stack. Imagine the current call of the manager function is the topmost call. It splits the list into subsections of one. These will be not be recursively split again but will be combined in sorted order. This call will then return a sorted list of two. This call will of course be recursively called by the next copy down in the stack of the manager function, so the sorted list of two will be combined with another sorted list (maybe of two again) to produce a sorted list of four. The third-from-top in the stack call of the manager function will then return a sorted list of four to the third copy down in the stack, which will combine two sorted lists of four into a sorted list of eight, and so on.
- Merge the two sublists in sorted order, as described above.
- Return the merged and sorted list as indicated in the recursion discussion above.
Complexity of merge sort
The complexity of merge sort is O(n log n).
Like quicksort it features a halving of the dataset size per level of recursion thus the number of recursion levels is approximately log n (actually 2*log n due to the need for both a split phase and a merge phase, but this will still be of form log n). Per level, we have approximately n operations again (due to the merging process in which we pick the lowest current value between the to lists). So, multiply the two and we get O(n log n).
See here for a detailed explanation.
Unlike quicksort, however, it is not an in-place sorting algorithm as we have to split the original list into sub-lists. This comes with a small overhead. This allows us to consider advantages and disadvantages of merge sort and quicksort:
- Merge sort is reliably
O (n log n)while quicksort can beO(n^2)in worst cases. - Merge sort requires creation of new lists (which has a small overhead) while quicksort does not.
Exercises
Have a go at implementing quicksort in code.
If you finish that, have a go at implementing merge sort according to the description above. Hint: to split a list in two, use code such as the following:
import math